Streaming MySQL Results Using Java 8 Streams and Spring Data JPA
Since version 1.8, Spring data project includes an interesting feature - through a simple API call developer can request database query results to be returned as Java 8 stream. Where technically possible and supported by underlying database technology, results are being streamed one by one and are available for processing using stream operations. This technique can be particularly useful when processing large datasets (for example, exporting larger amounts of database data in a specific format) because, among other things, it can limit memory consumption in the processing layer of the application. In this article I will discuss some of the benefits (and gotchas!) when Spring Data streaming is used with MySQL database.
Naive approaches to fetching and processing a larger amount of data (by larger, I mean datasets that do not fit into the memory of the running application) from the database will often result with running out of memory. This is especially true when using ORMs / abstraction layers such as JPA where you don't have access to lower level facilities that would allow you to manually manage how data is fetched from the database. Typically, at least with the stack that I'm usually using - MySQL, Hibernate/JPA and Spring Data - the whole resultset of a large query will be fetched entirely either by MySQL's JDBC driver or one of the aforementioned frameworks that come after it. This will lead to OutOfMemory exceptions if the resultset is sufficiently large.
Solution Using Paging
Let's focus on a single example - exporting results of a large query as a CSV file. When presented with this problem and when I want to stay in Spring Data/JPA world, I usually settle for a paging solution. The query is broken down to smaller queries that each return one page of results, each with a limited size. Spring Data offers nice paging/slicing feature that makes this approach easy to implement. Spring Data's PageRequests get translated to limit/offset queries in MySQL. There are caveats though. When using JPA, entities get cached in EntityManager's cache. This cache needs to be cleared to enable garbage collector to remove the old result objects from the memory.
Let's take look how an actual implementation of paging strategy behaves in practice. For testing purposes I will use a small application based on Spring Boot, Spring Data, Hibernate/JPA and MySQL. It's a todo list management webapp and it has a feature to download all todos as a CSV file. Todos are stored in a single MySQL table. The table has been filled with 1 million entries. Here's the code for the paging/slicing export function:
@RequestMapping(value = "/todos2.csv", method = RequestMethod.GET)
public void exportTodosCSVSlicing(HttpServletResponse response) {
final int PAGE_SIZE = 1000;
response.addHeader("Content-Type", "application/csv");
response.addHeader("Content-Disposition", "attachment; filename=todos.csv");
response.setCharacterEncoding("UTF-8");
try {
PrintWriter out = response.getWriter();
int page = 0;
Slice<Todo> todoPage;
do {
todoPage = todoRepository.findAllBy(new PageRequest(page, PAGE_SIZE));
for (Todo todo : todoPage) {
String line = todoToCSV(todo);
out.write(line);
out.write("\n");
}
entityManager.clear();
page++;
} while (todoPage.hasNext());
out.flush();
} catch (IOException e) {
log.info("Exception occurred " + e.getMessage(), e);
throw new RuntimeException("Exception occurred while exporting results", e);
}
}
This how memory usage looks like while export operation is in progress:
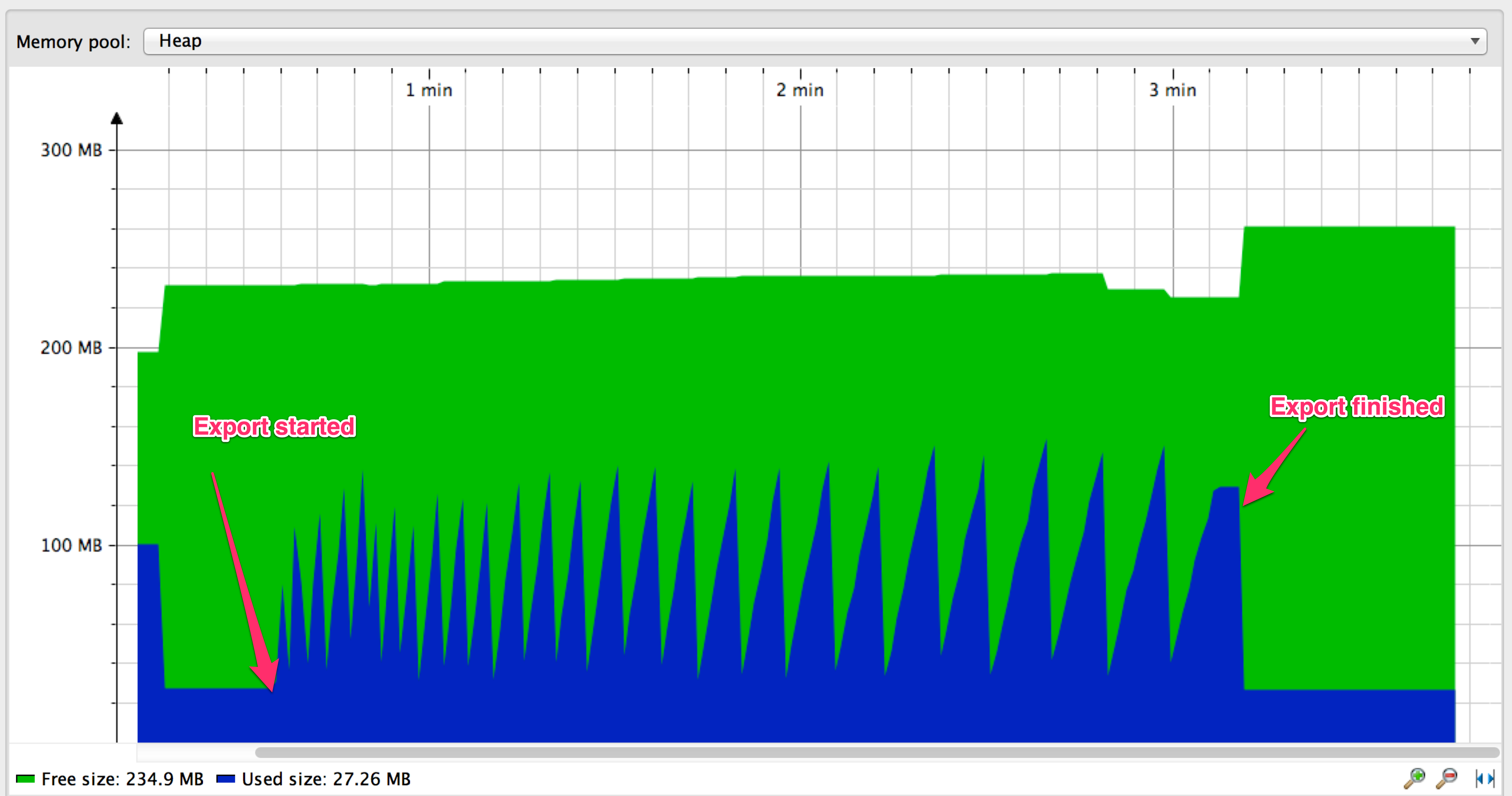
Memory usage graph has a shape of a saw-tooth: memory usage grows as entries are fetched from the database until GC kicks in and cleans up the entries that have already been outputted and cleared from EntityManager's cache. Paging approach works great but it definitely has room from improvement:
-
We're issuing 1000 database queries (number of entries / PAGE_SIZE) to complete the export. It would be better if we could avoid the overhead of executing those queries.
-
Did you notice how the raising slope of the tooths on the graph is less and less steep as the export progresses and the distance between the peaks increases? It seems that the rate at which new entires are fetched from DB gets slower and slower. The reason for this is MySQL's limit/offset performance characteristic - as offset gets larger it takes more and more time to find and return the selected rows.
Can we improve the above using new streaming functionality available in Spring Data 1.8? Let's try.
Streaming Functionality in Spring Data 1.8
Spring Data 1.8 introduced support for streaming resultsets. Repositories can now declare methods that return Java 8 streams of entity objects. For example, it's now possible to add a method with the following signature to a repository:
@Query("select t from Todo t")
Stream<Todo> streamAll();
Spring Data will use techniques specific to a particular JPA implementation (e.g. Hibernate's, EclipseLink's etc.) to stream the resultset. Let's re-implement the CSV exporting using this streaming capability:
@RequestMapping(value = "/todos.csv", method = RequestMethod.GET)
@Transactional(readOnly = true)
public void exportTodosCSV(HttpServletResponse response) {
response.addHeader("Content-Type", "application/csv");
response.addHeader("Content-Disposition", "attachment; filename=todos.csv");
response.setCharacterEncoding("UTF-8");
try(Stream<Todo> todoStream = todoRepository.streamAll()) {
PrintWriter out = response.getWriter();
todoStream.forEach(rethrowConsumer(todo -> {
String line = todoToCSV(todo);
out.write(line);
out.write("\n");
entityManager.detach(todo);
}));
out.flush();
} catch (IOException e) {
log.info("Exception occurred " + e.getMessage(), e);
throw new RuntimeException("Exception occurred while exporting results", e);
}
}
I started the export as usual, however the results are not showing up. What's happening?
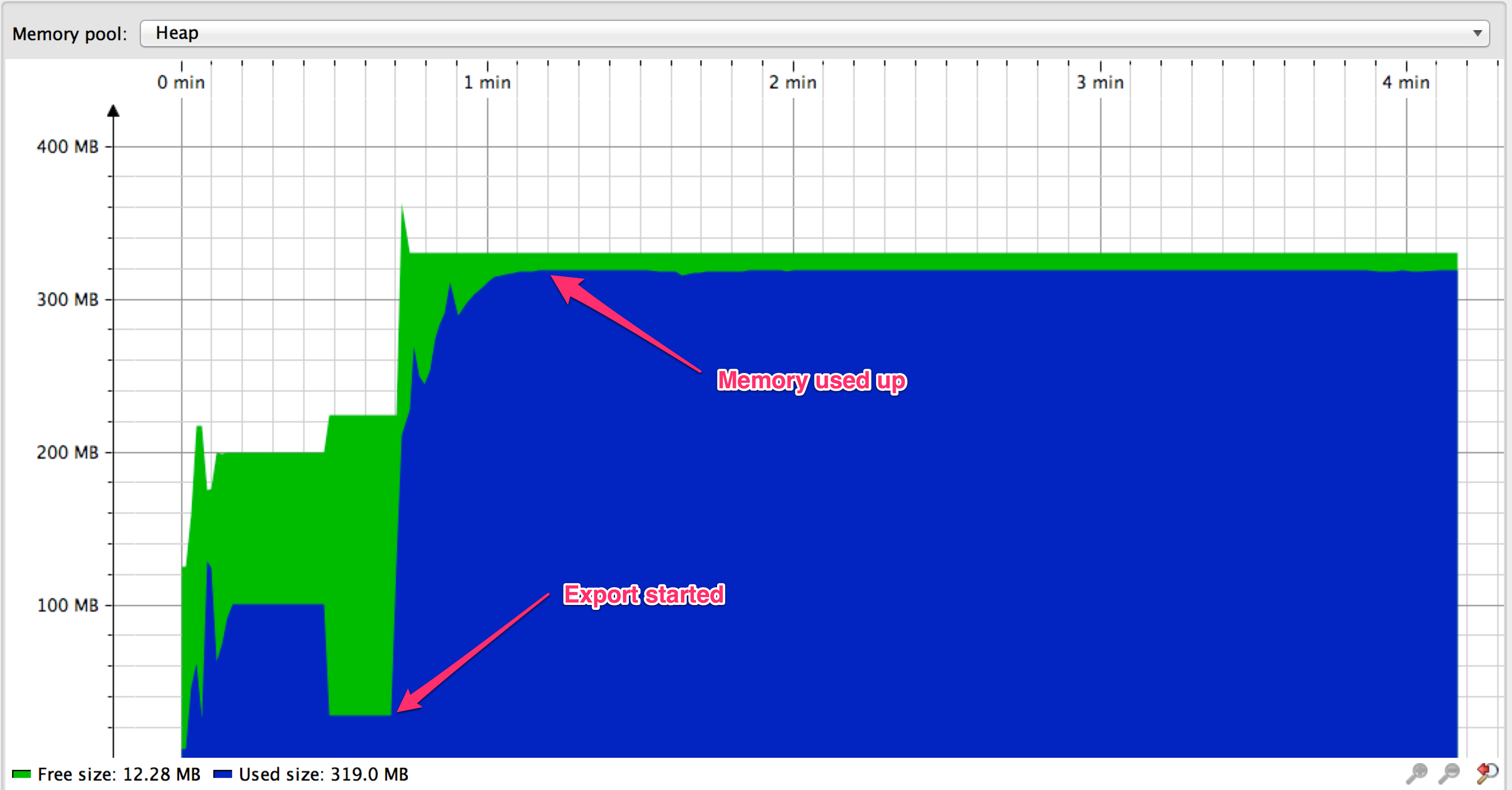
It seems that we have run out of memory. Additionally, no results were written to HttpServletResponse. Why isn't this working? After digging into source code of org.springframework.data.jpa.provider.PersistenceProvider one can find out that Spring Data is using scrollable resultsets to implement resultset streams. Googling about scrollable resultsets and MySQL shows that there are gotchas when using them. For instance, here's a quote from MySQL's JDBC driver's documentation:
By default, ResultSets are completely retrieved and stored in memory. In most cases this is the most efficient way to operate and, due to the design of the MySQL network protocol, is easier to implement. If you are working with ResultSets that have a large number of rows or large values and cannot allocate heap space in your JVM for the memory required, you can tell the driver to stream the results back one row at a time. To enable this functionality, create a Statement instance in the following manner:
stmt = conn.createStatement(java.sql.ResultSet.TYPE_FORWARD_ONLY,java.sql.ResultSet.CONCUR_READ_ONLY); stmt.setFetchSize(Integer.MIN_VALUE);The combination of a forward-only, read-only result set, with a fetch size of Integer.MIN_VALUE serves as a signal to the driver to stream result sets row-by-row. After this, any result sets created with the statement will be retrieved row-by-row.
There are some caveats with this approach. You must read all of the rows in the result set (or close it) before you can issue any other queries on the connection, or an exception will be thrown.
Ok, it seems that when using MySQL in order to really stream the results we need to satisfy three conditions:
- Forward-only resultset
- Read-only statement
- Fetch-size set to Integer.MIN_VALUE
Forward-only seems to be set already by Spring Data so we don't have to do anything special about that. Our code sample already has @Transactional(readOnly = true) annotation which is enough to satisfy the second criteria. What seems to be missing is the fetch-size. We can set it up using query hints on the repository method:
...
import static org.hibernate.jpa.QueryHints.HINT_FETCH_SIZE;
@Repository
public interface TodoRepository extends JpaRepository<Todo, Long> {
@QueryHints(value = @QueryHint(name = HINT_FETCH_SIZE, value = "" + Integer.MIN_VALUE))
@Query(value = "select t from Todo t")
Stream<Todo> streamAll();
...
}
With query hints in place, let's run export again:
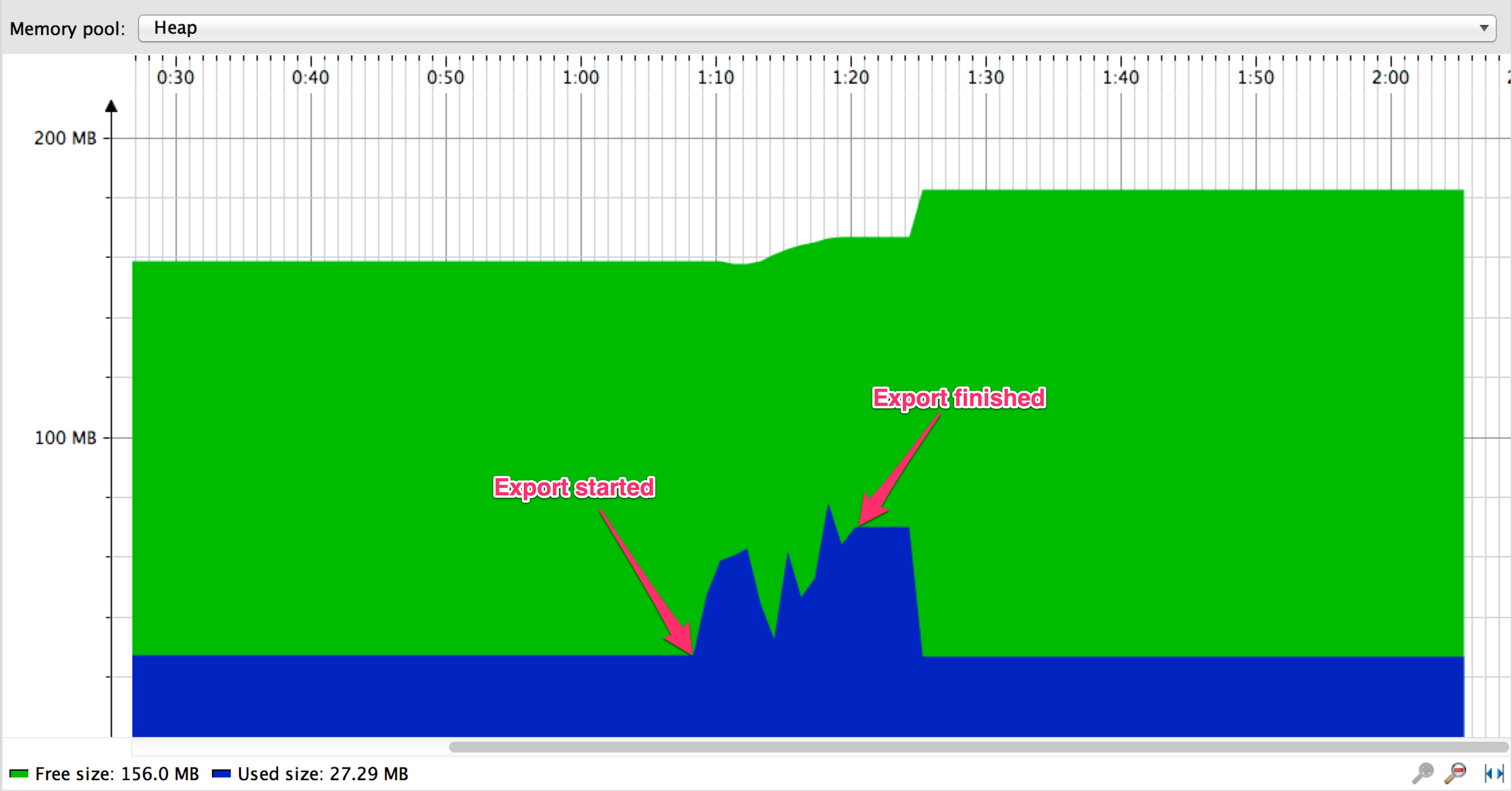
Everything is working now, and it seems it's much more efficient than the paging approach:
- When streaming, export is finished in about 9 seconds vs about 137 seconds when using paging
- It seems offset performance, query overhead and result preloading can really hurt paging approach when dataset is sufficiently large
Conclusions
- We've seen significant performance improvements when using streaming (via scrollable resultsets) vs paging, admittedly in a very specific task of exporting data.
- Spring Data's new features give really convenient access to scrollable resultsets via streams.
- There are gotchas to get it working with MySQL, but they are manageable.
- There are further restrictions when reading scrollable result sets in MySQL - no statement may be issued through the same database connection until the resultset is fully read.
- The export works fine because we are writing results directly to
HttpServletResponse. If we were using default Spring's message converters (e.g. returning stream from the controller method ) then there's a good chance this would not work as expected. Here's an interesting article on this subject.
I would love to try the tests with other database and explore possibilities of streaming results via Spring message converters as hinted in article linked above. If you'd like to experiment yourself, the test application is available on github. I hope you found the article interesting and I welcome your comments in the comment section below.